Different types of Distances used in Machine Learning Explained!
Have you ever wondered that how a machine learning algorithm measure distance?i mean it cant see like us was and tell, or even for once this came to your mind that there can be more than one way to calculate distances.

When someone hears the word “Distance” they typically assumes that it is a numerical measurement of how far two points or objects is but when they hear it with the term Machine Learning they think is different. Well it is different rather completely different. So lets get started and know what is it in Machine Learning.
When we say distance, what we mean is the distance metrics and the basic Mathematics Definition, Distance metric uses distance function which provides a relationship metric between each element in the datasets.
Several Machine Learning Algorithms — Supervised or Unsupervised, use Distance Metrics to know the input data pattern to make any Data-Based decision. A good distance metric helps in improving the performance of Classification, Clustering, and Information Retrieval process significantly.
Distance Metrics
There are many Distance Metrics ans in this article we are going to discuss about few of them.
Most common 4 Types of Distance Metrics in Machine Learning
- Euclidean Distance
- Manhattan Distance
- Minkowski Distance
- Hamming Distance
- L1, L2 and Lp norms
- Cosine Distance and Similarity
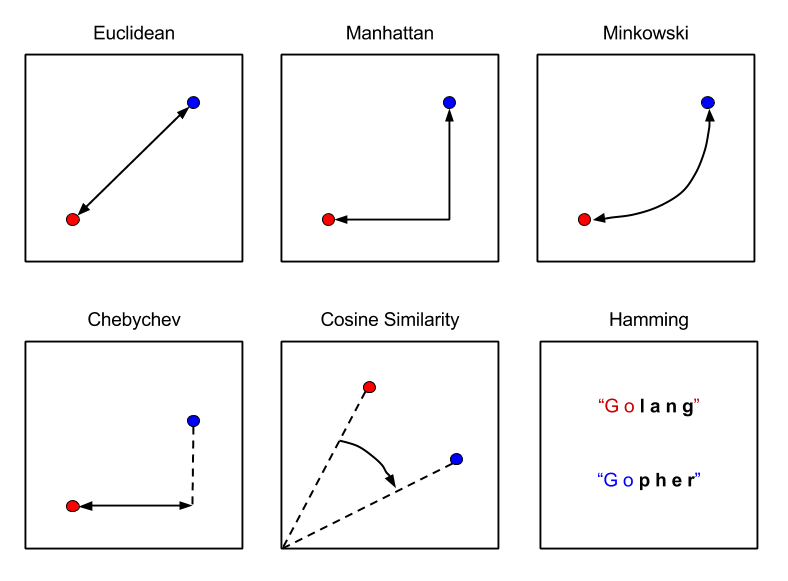

Euclidean Distance:
This is one of the most commonly used distance measures.
It is calculated as the square root of the sum of differences between each point.

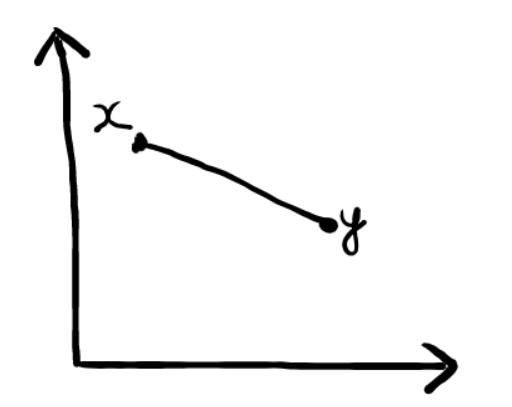
In simple words, Euclidean Distance represents the shortest distance between two points.
Euclidean distance is also known as the L2 norm of a vector.
L2 norm:
It is the most popular norm, also known as the Euclidean norm. It is the shortest distance to go from one point to another.
Example, the L2 norm is calculated by
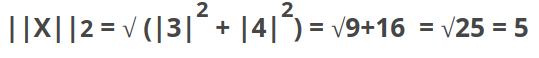
As you can see in the graphic, the L2 norm is the most direct route.
There is one consideration to take with the L2 norm, and it is that each component of the vector is squared, and that means that the outliers have more weighting, so it can skew results.
Most machine learning algorithms including K-Means use this distance metric to measure the similarity between observations. Let’s say we have two points as shown below:
So, the Euclidean Distance between these two points A and B will be:
Here’s the formula for Euclidean Distance:
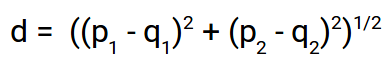
We use this formula when we are dealing with 2 dimensions. We can generalize this for an n-dimensional space as:
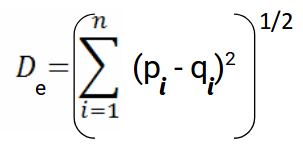
Where,
n = number of dimensions
pi, qi = data points
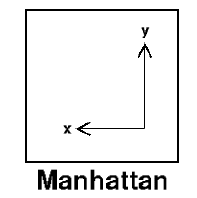
Manhattan Distance:
Manhattan Distance is the sum of absolute differences between points across all the dimensions. We use Manhattan Distance if we need to calculate the distance between two data points in a grid-like path. We use the Minkowski distance formula to find Manhattan distance by setting p’s value as 1.
Let’s say, we want to calculate the distance, d, between two data points- x and y.
Distance d will be calculated using an absolute sum of the difference between its cartesian coordinates as below :
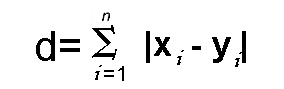
where, n- number of variables, xi and yi are the variables of vectors x and y respectively, in the two-dimensional vector space. i.e. x = (x1,x2,x3,…) and y = (y1,y2,y3,…).
Now the distance d will be calculated as-
(x1 — y1) + (x2 — y2) + (x3 — y3) + … + (xn — yn).
If you try to visualize the distance calculation, it will look something like as below :

Manhattan distance is also known as Taxicab Geometry, City Block Distance, etc.
When we can use a map of a city, we can give direction by telling people that they should walk/drive two city blocks North, then turn left and travel another three city blocks. In total, they will travel five city blocks, which is the Manhattan distance between the starting point and their destination.
L1 Norm:
Also known as Manhattan Distance or Taxicab norm. L1 norm is the sum of the magnitudes of the vectors in space. It is the most natural way of measure distance between vectors, that is the sum of absolute difference of the components of the vectors. In this norm, all the components of the vector are weighted equally.
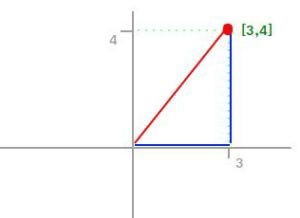
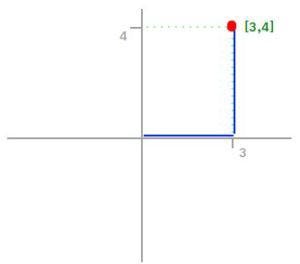
Having, for example, the vector X = [3,4]:
The L1 norm is calculated by
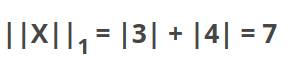
As you can see in the graphic, the L1 norm is the distance you have to travel between the origin (0,0) to the destination (3,4), in a way that resembles how a taxicab drives between city blocks to arrive at its destination.
Minkowski Distance:
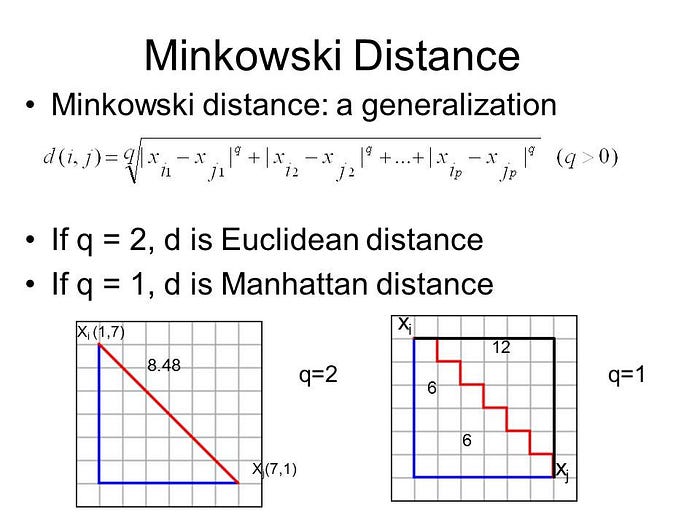
Minkowski Distance is the generalized form of Euclidean and Manhattan Distance.We can calculate Minkowski distance only in a normed vector space, which is a fancy way of saying: “in a space where distances can be represented as a vector that has a length.”
Let’s start by proving that a map is a vector space. If we take a map, we see that distances between cities are normed vector space because we can draw a vector that connects two cities on the map. We can combine multiple vectors to create a route that connects more than two cities. Now, the adjective “normed.” It means that the vector has its length and no vector has a negative length. That constraint is met too because if we draw a line between cities on the map, we can measure its length.
Again, a normed vector space is a vector space on which a norm is defined. Suppose X is a vector space then a norm on X is a real-valued function ||x||which satisfies below conditions -
- Zero Vector- Zero vector will have zero length. To say, If we look at a map, it is obvious. The distance from a city to the same city is zero because we don’t need to travel at all. The distance from a city to any other city is positive because we can’t travel -20 km.
2. Scalar Factor- The direction of the vector doesn’t change when you multiply it with a positive number though its length will be changed. Example: We traveled 50 km North. If we travel 50 km more in the same direction, we will end up 100 km North. The direction does not change.
3. Triangle Inequality- If the distance is a norm then the calculated distance between two points will always be a straight line.
Hamming Distance:

Hamming Distance measures the similarity between two strings of the same length. The Hamming Distance between two strings of the same length is the number of positions at which the corresponding characters are different.
We use hamming distance if we need to deal with categorical attributes.
Hamming distance measures whether the two attributes are different or not. When they are equal, the distance is 0; otherwise, it is 1.
We can use hamming distance only if the strings are of equal length.
A Hamming distance in information technology represents the number of points at which two corresponding pieces of data can be different. It is often used in various kinds of error correction or evaluation of contrasting strings or pieces of data.
Why is this important? One fundamental application of Hamming distance is to correct binary code either toward one result or another. Professionals talk about one-bit errors or two-bit errors, the idea that corrupted data can be transformed into a correct original result. The problem is, if there are two strings and one corrupted piece of data, one must ascertain which final result the corrupted or third data set is closest to. That is where the Hamming distance comes in — for example if the Hamming distance is four, and there is a one-bit error toward one result, it is most likely that that is the correct result. This is just one of the applications that the Hamming distance can have toward code and data string evaluation.
Example:
Suppose there are two strings 1101 1001 and 1001 1101.
11011001 ⊕ 10011101 = 01000100. Since, this contains two 1s, the Hamming distance, d(11011001, 10011101) = 2.
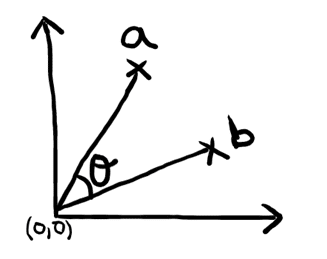
COSINE SIMILARITY:
It measures the cosine angle between the two vectors.
Cosine similarity ranges from 0 to 1, where 1 means the two vectors are perfectly similar.
If the angle between two vectors increases then they are less similar.
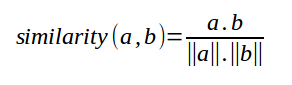
Cosine similarity cares only about the angle between the two vectors and not the distance between them.
Cosine Similarity and Cosine Distance:
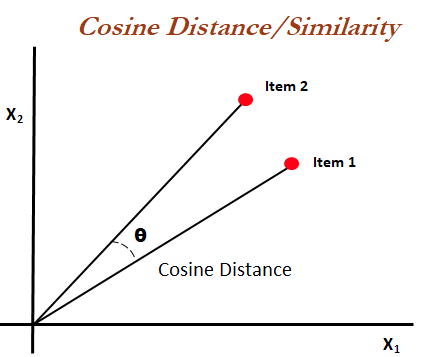
There are two terms: Similarity and Distance. They are inversely proportional to each other i.e if one increases the other one decreases and vice-versa. the formula for which is:
1-cos_sin=cos_distance
Cosine similarity formula can be derived from the equation of dot products:-
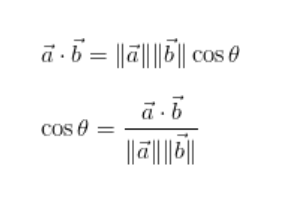
Now, you must be thinking which value of cosine angle will help find out the similarities.
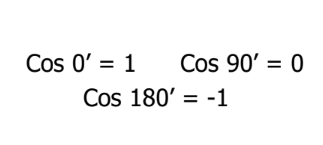
Now that we have the values which will be considered to measure the similarities, we need to know what do 1, 0 and -1 signify.
Here cosine value 1 is for vectors pointing in the same direction i.e. there are similarities between the documents/data points. At zero for orthogonal vectors i.e. Unrelated(some similarity found). Value -1 for vectors pointing in opposite directions(No similarity).
To find the cosine distance, we simply have to put the values in the formula and compute.
I hope after reading this article, now you have a vast knowledge about Distances so don’t get confused again when someone talks about distances in front of you because now you know more than ever about distance both in case of mathematics and Machine Learning.
Oh, please don’t forget to clap. Thank You:)

